Tahiti构架奥义探秘 HD7950比HD7970还快
Shader灵活度测试:矩阵乘法
矩阵乘法是线性代数的基本构成之一,它是各种通用计算以及Shader处理过程中非常常见的数学操作方式,矩阵乘法的过程可以将许多非常复杂的模型转换成相对简单的表现形式,因此被广泛应用在了光栅化(坐标变换)、光照(亮度直方操作)、阴影边缘平滑(针对像素块的切比雪夫不等式群)等几乎所有图形处理过程中。可以说只要进行图形处理过程,GPU就必定会进行大量的矩阵乘法操作。

矩阵乘法
矩阵乘法可以被解离成大量的行列式运算,并行化的处理这些行列式,同时为操作过程提供合理的缓冲空间来释放临时结果势必会极大地加快矩阵乘法操作的效率,进而加快整个图形过程的进度。因此,对于矩阵乘法效率的测试,不仅可以让我们获得构架并行度以及缓冲资源情况的信息,更能在趋势上反映GPU执行Shader尤其是灵活Shader的执行效率。所以,我们将矩阵乘法测试作为构架延展测试的第一个项目,通过它将Tahiti构架的ALU团簇部分剥离出来进行专门的性能测试。
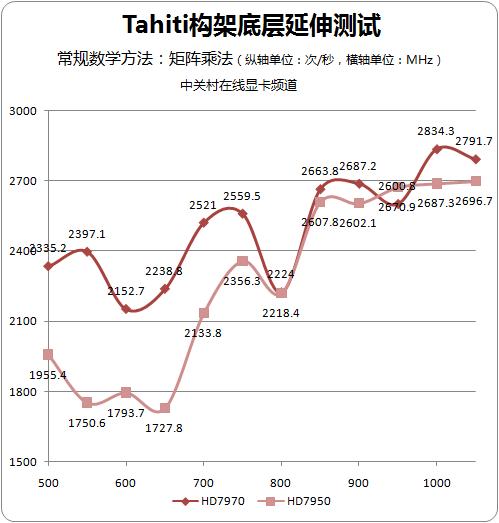
HD7950的运算单元规模比HD7970缩减了12.5%,但各项缓冲资源比如二级统一缓存的总量并未见变化,所以HD7950的每一个ALU所能够获得的寄存器溢出缓冲会高于HD7970。正因为此,虽然同为Tahiti构架,但伴随着频率的提升,HD7970以及HD7950在执行矩阵乘法时的性能差距在快速缩小,更大的缓冲密度为HD7950带来了更好的单元复用率,这种更好的单元动作效率不仅成功的弥合了由运算单元吞吐规模带来的差异,更让HD7950拥有了更好的执行各种灵活Shader指令的能力。
Shader灵活度测试:矩阵转置
矩阵转置同矩阵乘法一样,也广泛分布在包括坐标变换等过程在内的大量图形处理过程中。矩阵转置可以被理解成矩阵沿特定方向“翻转”之后产生的镜像,这导致了矩阵转置操作会涉及到大量数据,比如稀疏矩阵的对角线数据等的临时存储,因此矩阵转置操作对于体系的缓冲密度是相当敏感的。
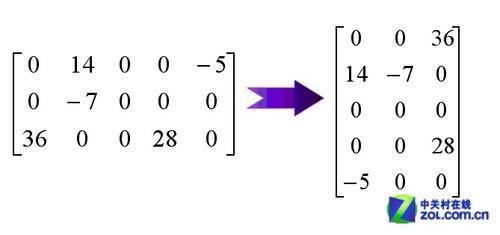
矩阵转置操作
同矩阵乘法一样,伴随着频率的不断提升,HD7950的矩阵转置性能提升速度较之HD7970要高出许多,两者之间的性能差异在迅速的收窄甚至趋同。由于矩阵转置的操作过程较之矩阵乘法更加“规整”,能够产生瞬间高延迟的因素较少,因此矩阵转置测试所得的趋势也更加明显和直观。
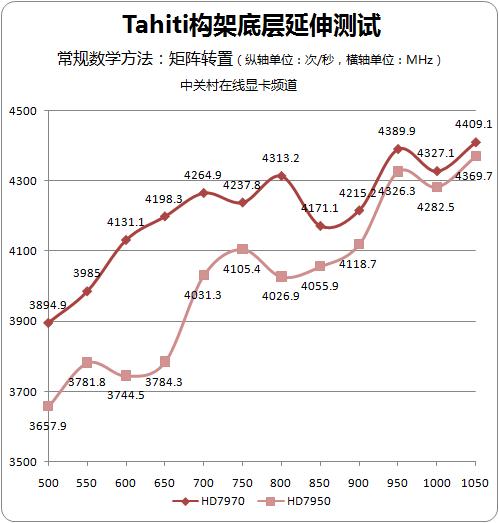
矩阵系操作的测试明白无疑的向我们传达了一个信息——HD7950拥有比HD7970更好的单元复用率。这种单元复用率的差异以及其背后缓冲密度提升带来不仅佐证了我们反复强调的关于Tahiti构架单元复用率虽然改善良多但依旧不足的观点,更为“HD7950的图形性能有没有超越HD7970”这一问题埋下了伏笔。

-
 《LOL》第一位女性暗裔要来了?巴西老哥又爆猛料
《LOL》第一位女性暗裔要来了?巴西老哥又爆猛料
 黑五PS5优惠力度太大!限定机捆绑机卖脱销
黑五PS5优惠力度太大!限定机捆绑机卖脱销
-
 《守望2》新女角色被批"身材太好"?设计师亲自回怼
《守望2》新女角色被批"身材太好"?设计师亲自回怼
 TGA神秘骷髅雕像坐落现实!玩家实地打卡:急死了
TGA神秘骷髅雕像坐落现实!玩家实地打卡:急死了
-
 情况有变!《霍格沃茨》新作或仍是单人RPG 联动HBO
情况有变!《霍格沃茨》新作或仍是单人RPG 联动HBO
 擅长安慰寂寞少妇 曹操来了都说操的囧图
擅长安慰寂寞少妇 曹操来了都说操的囧图
- 网友在父亲遗物翻出"18x格斗游戏":父亲的威严尽失了
- 《妮姬》新皮肤太绝!不穿裤子只穿丝袜曲线拉满!
- 他简直是机器人!Faker精准5s读秒掐表震惊网友
- 6916元礼包惊喜价出售!《暗黑4》国服回归福利炸裂
- 成人MOD作者被玩家吓坏:怎么有这么多人玩?
- 英国女警卧底5年爱上目标 闪婚隐居 伦敦警方道歉
- 抓紧提现!《CS2》知名皮肤交易平台破产停运
- 这是哪个大ip的新作?TGA主持人发神秘截图引爆讨论
- 不行这真有点大!坚称胸部为天然原生的巨乳樱花妹
- 美国女星撞脸《2077》帕南? 大方cos玩游戏!


- 《Eclipse Breaker》官方正版下载
- 《淘金热》官方中文版下载
- 《Hangtime!》官方正版下载
- 《霓虹地狱》官方中文版下载
- 《The Last Case of John Morley》官方中文版下载
- 《仓库猎人模拟器》官方中文版下载
- 《Lonely House》官方中文版下载
- 《凛冬前线》官方中文版下载
-
 发布时间:2025-11-30
发布时间:2025-11-30 -
 发布时间:2025-11-28
发布时间:2025-11-28 -
 发布时间:2025-11-28
发布时间:2025-11-28








