再次夺回“帝王”宝座!GTX 690详细评测
● 高频好助手——SMX单元
SM是NVIDIA GPU的ALU团簇基本单元,在Kepler中SM部分的改进可谓翻天覆地,NVIDIA采用的全新的SMX单元彻底改变了传统的SM单元的内涵,它在赋予整个体系极高的性能功耗比的同时,直接导致了今天这样完整规格同时默认运行频率极高的Geforce GTX690的诞生。
Kepler所采用的SMX单元与Fermi的SM单元在逻辑结构上十分近似,都拥有完整的几何前端,线程仲裁机制,ALU团簇,Texture Array以及unified cache/shared和Register。除了没有后端之外,可以说一个SM/SMX单元在结构上已经趋近等同于一颗标准GPU了。
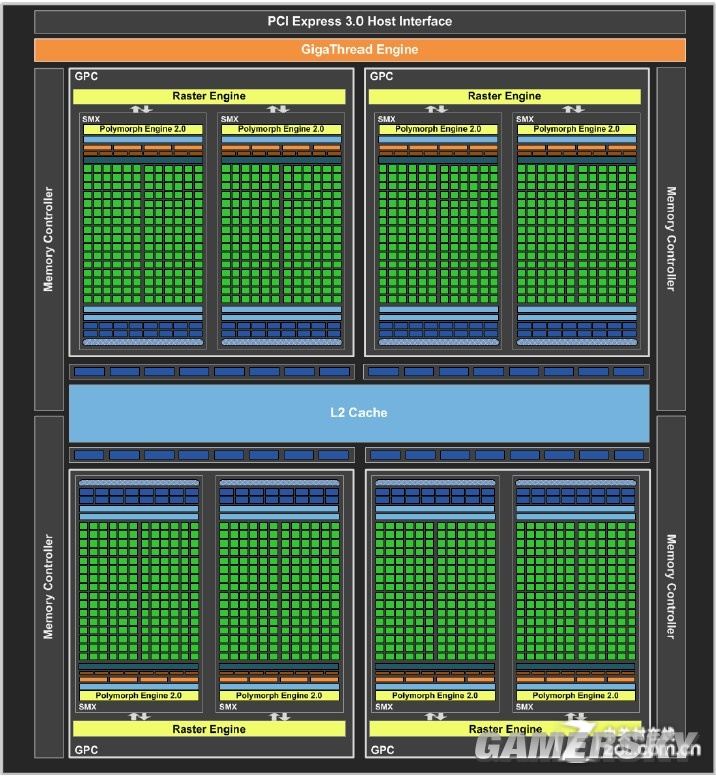
GK104逻辑架构
与Fermi的SM单元规模对应线程粒度单位warp(32 ALU VS 32 Thread)不同,Kepler的SMX单元急剧放大了ALU团簇的整体规模,其ALU总量从过去的32个增加到了192个。与此同时,SMX单元的线程仲裁管理机制也得到了绝对数量上的放大。负责线程分派和发放管理的Warp Scheduler从过去的2个增加到了4个,与之对应的Dispatch Unit从过去的2个增加到了8个,Warp Scheduler与Dispatch Unit的比例提升变成了1:2。

SMX单元结构
在放大ALU团簇的同时,NVIDIA还进一步放大了与ALU团簇对应的Register。根据NVIDIA提供的资料,GK104架构中每个SMX的Register较之Fermi的SM放大了一倍,达到了65536X32bit的规模。
在Unified Cache体系方面,Kepler与传统的Fermi在结构上没有多大的差异,其L1/shared以及L2 cache的大小和比例均未发生变化,仍旧维持64K的L1/Shared以及128K/MC的L2尺寸。整个体系中最值得关注的变动来自L2 cache速度以及带宽的提升,NVIDIA称Kepler的L2 cache目前运行在分频状态下,默认运行频率是核心频率的一倍,这为GK104提供了比过去大得多的L2带宽,这为通用计算性能以及Texture性能的提升创造了有利的条件。

更为强劲的SMX性能
更大的ALU规模、更多的线程仲裁机制以及更大的寄存器缓冲为SMX带来了全新的性能表现,新的逻辑设计让Kepler的运算单元拥有了2倍于Fermi的性能功耗比。更高的能耗比为单卡双芯的设计减轻了很多功耗层面的负担,因此GeForce GTX690得意以完整的GK104芯片规模运行在更高的频率之上,并以此获得了毫无争议的性能王座。
- 第1页:又一个打破“规律”的王者
- 第2页:性能王座拥有者的更多细节
- 第3页:高频好助手——SMX单元解析
- 第4页:全新的Pre-Scheduling过程
- 第5页:更宽泛的GPU Boost调节频率
- 第6页:拒绝画面撕裂:主动式垂直同步
- 第7页:全新边缘检查抗锯齿:TXAA
- 第8页:依旧可以达成的单卡多屏
- 第9页:NVENC:硬件H264编码引擎
- 第10页:第一位穿“铠甲”的皇帝
- 第11页:卡皇全家福
- 第12页:测试平台及测试项目简介
- 第13页:理论性能测试:3DMark Series
- 第14页:DirectX 9.0C游戏测试:CWOW-CTM
- 第15页:DirectX 10游戏测试:Crysis
- 第16页:DirectX 10游戏测试:FarCry 2
- 第17页:DirectX 11游戏测试:BattleField 3
- 第18页:DirectX 11游戏测试:Crysis2
- 第19页:DirectX 11游戏测试:Call of Duty MW3
- 第20页:DirectX 11游戏测试:Metro 2033
- 第21页:DirectX 11游戏测试:H.A.W.X 2
- 第22页:DirectX 11游戏测试:LostPlanet 2
- 第23页:DirectX 11应用测试:天堂3.0
- 第24页:游戏性能综合比率
- 第25页:功耗温度及性能功耗比测试
- 第26页:测试总结:显卡发展重回正轨

-
 《LOL》第一位女性暗裔要来了?巴西老哥又爆猛料
《LOL》第一位女性暗裔要来了?巴西老哥又爆猛料
 黑五PS5优惠力度太大!限定机捆绑机卖脱销
黑五PS5优惠力度太大!限定机捆绑机卖脱销
-
 《守望2》新女角色被批"身材太好"?设计师亲自回怼
《守望2》新女角色被批"身材太好"?设计师亲自回怼
 TGA神秘骷髅雕像坐落现实!玩家实地打卡:急死了
TGA神秘骷髅雕像坐落现实!玩家实地打卡:急死了
-
 情况有变!《霍格沃茨》新作或仍是单人RPG 联动HBO
情况有变!《霍格沃茨》新作或仍是单人RPG 联动HBO
 擅长安慰寂寞少妇 曹操来了都说操的囧图
擅长安慰寂寞少妇 曹操来了都说操的囧图
- 网友在父亲遗物翻出"18x格斗游戏":父亲的威严尽失了
- 《妮姬》新皮肤太绝!不穿裤子只穿丝袜曲线拉满!
- 他简直是机器人!Faker精准5s读秒掐表震惊网友
- 6916元礼包惊喜价出售!《暗黑4》国服回归福利炸裂
- 成人MOD作者被玩家吓坏:怎么有这么多人玩?
- 英国女警卧底5年爱上目标 闪婚隐居 伦敦警方道歉
- 抓紧提现!《CS2》知名皮肤交易平台破产停运
- 这是哪个大ip的新作?TGA主持人发神秘截图引爆讨论
- 不行这真有点大!坚称胸部为天然原生的巨乳樱花妹
- 美国女星撞脸《2077》帕南? 大方cos玩游戏!


- 《Eclipse Breaker》官方正版下载
- 《淘金热》官方中文版下载
- 《Hangtime!》官方正版下载
- 《霓虹地狱》官方中文版下载
- 《The Last Case of John Morley》官方中文版下载
- 《仓库猎人模拟器》官方中文版下载
- 《Lonely House》官方中文版下载
- 《凛冬前线》官方中文版下载
-
 发布时间:2025-11-28
发布时间:2025-11-28 -
 发布时间:2025-11-28
发布时间:2025-11-28 -
 发布时间:2025-11-28
发布时间:2025-11-28








