再次夺回“帝王”宝座!GTX 690详细评测
● 全新的Pre-Scheduling过程
早在GeForce GTX680的首测的过程中,Kepler架构全新的Scheduling过程就引起了我们极大的兴趣,它是Kepler众多“黑科技”中隐藏最深同时可能产生的影响也最为深远的改进之一。由于ISA结构资料的缺失以及测试初期对底层架构信息掌握的不足,我们在当时无法了解这一改进的细节。伴随着信息收集以及后续测试的不断深入,我们现在终于获得了足够的细节,同时也成功的将它与GK104的SMX结构改进以及NVIDIA的架构发展过程联系在了一起。
GPU的逻辑结构决定了它并不适合被用来执行关联度过高过深的条件分支过程,因此对于任务的关联性检查以及将关联指令打散到不同的线程块中就成了整个GPU任务队列执行过程中一个非常重要的步骤。在以Fermi为代表的传统仲裁体系中,任务会在解码过程之后完成指令的关联性检查,如果指令存在超过一定限度的关联性,为了规避条件分支对性能产生的影响,这些指令会被重新打包以便ALU团簇进行吞吐。在完成这些关联性检查之后,明确执行方向的指令才会被送入流水线中进行执行。为了加快这一过程的速度,Fermi架构为这个过程提供了Multiport Post decode Queue以及对应Register的硬件支持。这部分工作执行的场所以及Multiport Post decode Queue和对应Register所处的位置,就在SM单元的Logic controller。
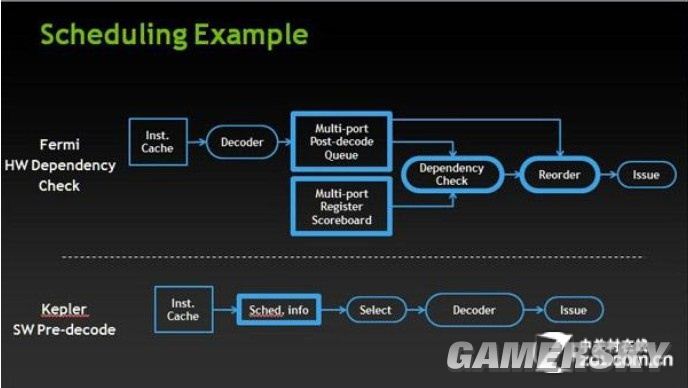
Kepler引入的全新Scheduling过程
在Kepler中,这一传统的过程发生了巨大的变化,任务会在进入GPU之前先根据Sched.info进行关联度判断以及选择,然后直接进行解码并被送入流水线中完成后续处理。传统的关联性检查以及指令重组等过程被Sched.info-select所取代。在执行过Pre-Scheduling过程之后,指令从解码到执行之间的延迟被大幅降低,整个流水线因此获得了更高的执行效率和复用率。而执行这一过程的场合也不再是SMX单元的Logic controller,它被挪到了我们熟悉的X86处理器,也就是你主板上插着的那颗CPU中。

Fermi架构SM单元内部的Scheduler以及Dispatch Unit比例
由于新的Scheduling过程在CPU中基于软件形式完成,因此传统Logic controller中与Pre-Scheduling相关的硬件,比如Fermi中的Multiport Post decode Queue(解码后队列)以及对应的Register(寄存器)等等DCA(Dependency check Architecture,负责依赖性检查的逻辑结构)也就没有了存在的必要,它们所占用的晶体管资源可以被释放出来,Logic controller的规模也因此得以大幅削减。尽管目前的Pre-Scheduling只涉及中等以下关联性的检查,并没有完全取代全部的Scheduling动作,关联度较深的指令依旧需要传统的硬件DCA来快速执行,但这一改进还是促使NVIDIA将SMX中Warp Scheduler的密度削减到了Fermi的1/3。

Fermi的SM单元结构比例
除此之外,Pre-Scheduling让指令从解码到执行之间的过程变得更加简洁,从线程进入SMX到抵达ALU进行执行这一过程的延迟也被降低。延迟的缩短缓解了线程派发效率带来的负担,让硬件不再需要配备大量的分派资源来提升任务分派的效率,以便抵充前面延迟所带来的性能损失,因此SMX单元中的Dispatch Unit密度也随之得以降低。在SMX中,NVIDIA配给的Dispatch Unit密度只有Fermi的66%。

Kepler的SMX单元结构比例
DCA的大量削减以及Warp Scheduler和Dispatch Unit密度的下降促成了Logic controller的的最终瘦身,这不仅直接导致了NVIDIA可以放心大胆的扩张SMX单元的规模,将更多ALU资源纳入到GPU体系中去,更成功的将传统DCA硬件运行过程的功耗转移到了CPU当中。有了更多直接运算资源带来的性能,同时功耗矛盾也得到了缓解,基于Kepler构架的GeForce GTX690拥有目前的单卡性能王座也就不是什么奇怪的事情了。
- 第1页:又一个打破“规律”的王者
- 第2页:性能王座拥有者的更多细节
- 第3页:高频好助手——SMX单元解析
- 第4页:全新的Pre-Scheduling过程
- 第5页:更宽泛的GPU Boost调节频率
- 第6页:拒绝画面撕裂:主动式垂直同步
- 第7页:全新边缘检查抗锯齿:TXAA
- 第8页:依旧可以达成的单卡多屏
- 第9页:NVENC:硬件H264编码引擎
- 第10页:第一位穿“铠甲”的皇帝
- 第11页:卡皇全家福
- 第12页:测试平台及测试项目简介
- 第13页:理论性能测试:3DMark Series
- 第14页:DirectX 9.0C游戏测试:CWOW-CTM
- 第15页:DirectX 10游戏测试:Crysis
- 第16页:DirectX 10游戏测试:FarCry 2
- 第17页:DirectX 11游戏测试:BattleField 3
- 第18页:DirectX 11游戏测试:Crysis2
- 第19页:DirectX 11游戏测试:Call of Duty MW3
- 第20页:DirectX 11游戏测试:Metro 2033
- 第21页:DirectX 11游戏测试:H.A.W.X 2
- 第22页:DirectX 11游戏测试:LostPlanet 2
- 第23页:DirectX 11应用测试:天堂3.0
- 第24页:游戏性能综合比率
- 第25页:功耗温度及性能功耗比测试
- 第26页:测试总结:显卡发展重回正轨

-
 我的人生就像恋足癖碰到美人鱼 王刚留下的囧图
我的人生就像恋足癖碰到美人鱼 王刚留下的囧图
 曝PS6定价或仅600美元!是下代Xbox的一半?
曝PS6定价或仅600美元!是下代Xbox的一半?
-
 死亡搁浅2中配官方实机演示:要被peko洗脑了!
死亡搁浅2中配官方实机演示:要被peko洗脑了!
 数毛社评《黑神话》PS5更新:以阉割光照为代价
数毛社评《黑神话》PS5更新:以阉割光照为代价
-
 又一款"明末"游戏即将问世:能跟带娃寡妇深入交流?
又一款"明末"游戏即将问世:能跟带娃寡妇深入交流?
 国内美女《FF7》蒂法COS!还原度之高令人惊叹
国内美女《FF7》蒂法COS!还原度之高令人惊叹
- “浩浩妈”黑丝新图来了!全新影游Demo已上线
- 成人向游戏成Steam销量黑马 玩家下单率惊人!
- 印度大作《释放阿凡达》上线Steam!他帅得要命
- 今天是金卡戴珊45岁生日 脱离侃爷后腰臀比恢复正常
- 影视飓风商店爆单无奈半歇业 网友催促Tim去踩缝纫机
- 《忍者龙剑传4》 游民评测9分 动作游戏的极意
- 王自如回应发胖原因:在格力时不喝酒没人说实话
- 当事人已被抓!小米极氪对撞测试更多内幕公开
- LPL年度最佳新秀被曝私联女粉丝 二人缠绵两个多月
- 《忍者龙剑传4》M站开分83!火力全开 无比爽快


- 《Midori no Kaori》官方正版下载
- 《蜀汉再临:源起》官方中文版下载
- 《心跳大冒险:泰遇》官方中文版下载
- 《鸭鸭侦探:萨拉米香肠之谜》官方中文版下载
- 《魔法少女的魔女审判》官方中文版下载
- 《Graveyard Gunslingers》官方中文版下载
- 《夏努尔:银风传奇》官方正版下载
- 《NEO:美妙世界》官方正版下载
-
 发布时间:2025-10-21
发布时间:2025-10-21 -
 发布时间:2025-10-20
发布时间:2025-10-20 -
 发布时间:2025-10-20
发布时间:2025-10-20








